Introduction
Weave is a lightweight toolkit for tracking and evaluating LLM applications, built by Weights & Biases.
Our goal is to bring rigor, best-practices, and composability to the inherently experimental process of developing AI applications, without introducing cognitive overhead.
Get started by decorating Python functions with @weave.op().
Seriously, try the 🍪 quickstart 🍪 or ![]()
You can use Weave to:
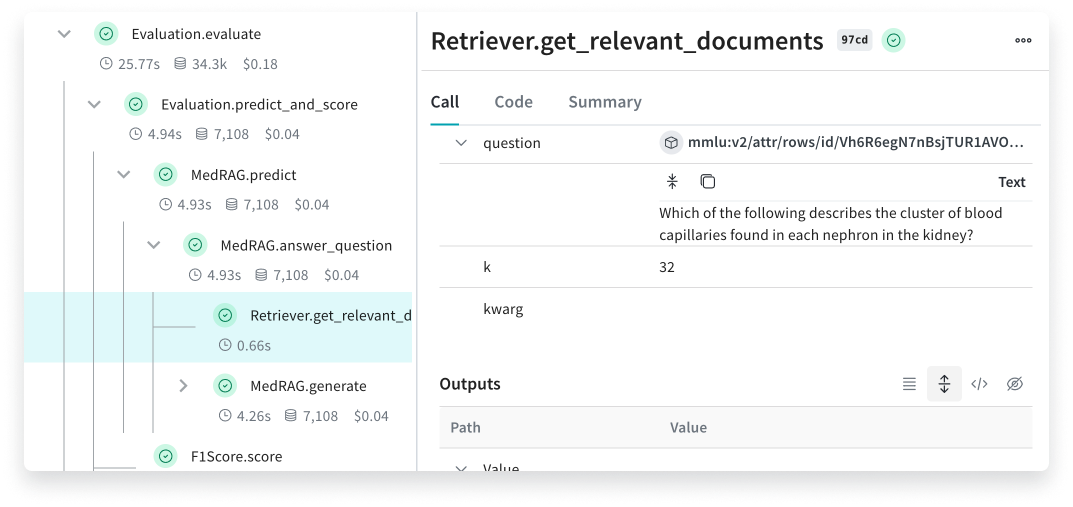
- Log and debug language model inputs, outputs, and traces
- Build rigorous, apples-to-apples evaluations for language model use cases
- Organize all the information generated across the LLM workflow, from experimentation to evaluations to production
Key concepts
Weave's core types layer contains everything you need for organizing Generative AI projects, with built-in lineage, tracking, and reproducibility.
- Datasets: Version, store, and share rich tabular data.
- Models: Version, store, and share parameterized functions.
- Evaluations: Test suites for AI models.
- [soon] Agents: ...
Weave's tracking layer brings immutable tracing and versioning to your programs and experiments.
- Objects: Weave's extensible serialization lets you easily version, track, and share Python objects.
- Ops: Versioned, reproducible functions, with automatic tracing.
- Tracing: Automatic organization of function calls and data lineage.
- Feedback: Simple utilities to capture user feedback and attach them to the underlying tracked call.
Weave offers integrations with many language model APIs and LLM frameworks to streamline tracking and evaluation:
- OpenAI: automatic tracking for openai api calls
- Anthropic
- Cohere
- MistralAI
- LangChain
- LlamaIndex
- DSPy
- Google Gemini
- Together AI
- Open Router
- Local Models
- LiteLLM
Weave's tools layer contains utilities for making use of Weave objects.
- Serve: FastAPI server for Weave Ops and Models
- Deploy: Deploy Weave Ops and Models to various targets
What's next?
Try the Quickstart to see Weave in action.